
 Amit Arora
701dc05be8
add FMBench
Amit Arora
701dc05be8
add FMBench
|
1 рік тому | |
|---|---|---|
| .. | ||
| img | 1 рік тому | |
| README.md | 1 рік тому | |
README.md
Benchmark Llama models on AWS
The FMBench tool provides a quick and easy way to benchmark the Llama family of models for price and performance on any AWS service including Amazon SagMaker, Amazon Bedrock or Amazon EKS or Amazon EC2 as Bring your own endpoint.
The need for benchmarking
Customers often wonder what is the best AWS service to run Llama models for my specific use-case and my specific price performance requirements. While model evaluation metrics are available on several leaderboards (HELM, LMSys), but the price performance comparison can be notoriously hard to find and even more harder to trust. In such a scenario, we think it is best to be able to run performance benchmarking yourself on either on your own dataset or on a similar (task wise, prompt size wise) open-source dataset (LongBench), QMSum. This is the problem that FMBench solves.
FMBench: an open-source Python package for FM benchmarking on AWS
FMBench runs inference requests against endpoints that are either deployed through FMBench itself (as in the case of SageMaker) or are available either as a fully-managed endpoint (as in the case of Bedrock) or as bring your own endpoint. The metrics such as inference latency, transactions per-minute, error rates and cost per transactions are captured and presented in the form of a Markdown report containing explanatory text, tables and figures. The figures and tables in the report provide insights into what might be the best serving stack (instance type, inference container and configuration parameters) for a given Llama model for a given use-case.
The following figure gives an example of the price performance numbers that include inference latency, transactions per-minute and concurrency level for running the Llama2-13b model on different instance types available on SageMaker using prompts for Q&A task created from the LongBench dataset, these prompts are between 3000 to 3840 tokens in length. Note that the numbers are hidden in this figure but you would be able to see them when you run FMBench yourself.
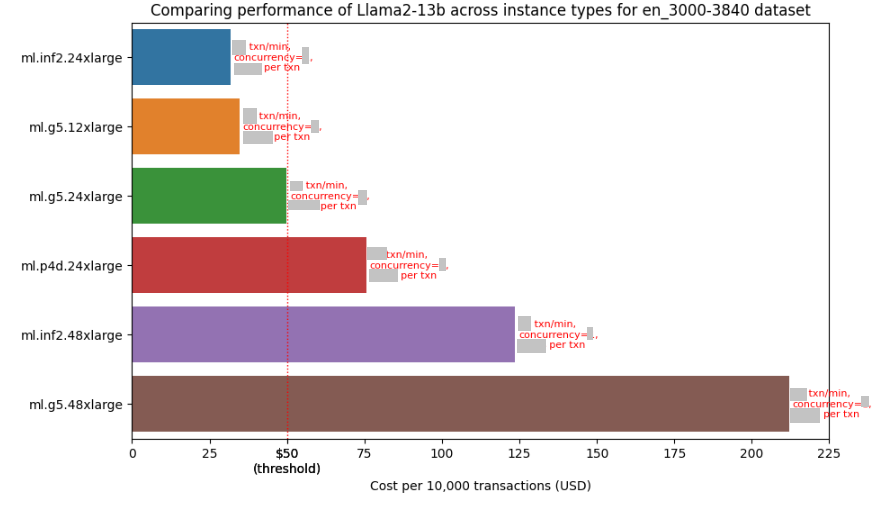
The following table (also included in the report) provides information about the best available instance type for that experiment1.
| Information | Value |
|---|---|
| experiment_name | llama2-13b-inf2.24xlarge |
| payload_file | payload_en_3000-3840.jsonl |
| instance_type | ml.inf2.24xlarge |
| concurrency | ** |
| error_rate | ** |
| prompt_token_count_mean | 3394 |
| prompt_token_throughput | 2400 |
| completion_token_count_mean | 31 |
| completion_token_throughput | 15 |
| latency_mean | ** |
| latency_p50 | ** |
| latency_p95 | ** |
| latency_p99 | ** |
| transactions_per_minute | ** |
| price_per_txn | ** |
1 ** represent values hidden on purpose, these are available when you run the tool yourself.
The report also includes latency Vs prompt size charts for different concurrency levels. As expected, inference latency increases as prompt size increases but what is interesting to note is that the increase is much more at higher concurrency levels (and this behavior varies with instance types).

How to get started with FMBench
The following steps provide a Quick start guide for FMBench. For a more detailed DIY version, please see the FMBench Readme.
- Launch the AWS CloudFormation template included in this repository using one of the buttons from the table below. The CloudFormation template creates the following resources within your AWS account: Amazon S3 buckets, Amazon IAM role and an Amazon SageMaker Notebook with this repository cloned. A read S3 bucket is created which contains all the files (configuration files, datasets) required to run
FMBenchand a write S3 bucket is created which will hold the metrics and reports generated byFMBench. The CloudFormation stack takes about 5-minutes to create.
|AWS Region | Link |
|:------------------------:|:-----------:|
|us-east-1 (N. Virginia) |  |
|us-west-2 (Oregon) | |
|
|us-west-2 (Oregon) | |
Once the CloudFormation stack is created, navigate to SageMaker Notebooks and open the
fmbench-notebook.On the
fmbench-notebookopen a Terminal and run the following commands.conda create --name fmbench_python311 -y python=3.11 ipykernel source activate fmbench_python311; pip install -U fmbenchNow you are ready to
fmbenchwith the following command line. We will use a sample config file placed in the S3 bucket by the CloudFormation stack for a quick first run.We benchmark performance for the
Llama2-7bmodel on aml.g5.xlargeand aml.g5.2xlargeinstance type, using thehuggingface-pytorch-tgi-inferenceinference container. This test would take about 30 minutes to complete and cost about $0.20.It uses a simple relationship of 750 words equals 1000 tokens, to get a more accurate representation of token counts use the
Llama2 tokenizer(instructions are provided in the next section). It is strongly recommended that for more accurate results on token throughput you use a tokenizer specific to the model you are testing rather than the default tokenizer. See instructions provided later in this document on how to use a custom tokenizer.account=`aws sts get-caller-identity | jq .Account | tr -d '"'` region=`aws configure get region` fmbench --config-file s3://sagemaker-fmbench-read-${region}-${account}/configs/config-llama2-7b-g5-quick.yml >> fmbench.log 2>&1Open another terminal window and do a
tail -fon thefmbench.logfile to see all the traces being generated at runtime.tail -f fmbench.log
The generated reports and metrics are available in the
sagemaker-fmbench-write-<replace_w_your_aws_region>-<replace_w_your_aws_account_id>bucket. The metrics and report files are also downloaded locally and in theresultsdirectory (created byFMBench) and the benchmarking report is available as a markdown file calledreport.mdin theresultsdirectory. You can view the rendered Markdown report in the SageMaker notebook itself or download the metrics and report files to your machine for offline analysis.
The config.yml file
Each FMBench run works with a configuration file that contains the information about the model, the deployment steps, and the tests to run. A typical FMBench workflow involves either directly using an already provided config file from the configs folder in the FMBench GitHub repo or editing an already provided config file as per your own requirements (say you want to try benchmarking on a different instance type, or a different inference container etc.).
A simple config file with some key parameters annotated is presented below. The file below benchmarks performance of Llama2-7b on an ml.g5.xlarge instance and an ml.g5.2xlarge instance.
general:
name: "llama2-7b-v1"
model_name: "Llama2-7b"
# AWS and SageMaker settings
aws:
# AWS region, this parameter is templatized, no need to change
region: {region}
# SageMaker execution role used to run FMBench, this parameter is templatized, no need to change
sagemaker_execution_role: {role_arn}
# S3 bucket to which metrics, plots and reports would be written to
bucket: {write_bucket} ## add the name of your desired bucket
# directory paths in the write bucket, no need to change these
dir_paths:
data_prefix: data
prompts_prefix: prompts
all_prompts_file: all_prompts.csv
metrics_dir: metrics
models_dir: models
metadata_dir: metadata
# S3 information for reading datasets, scripts and tokenizer
s3_read_data:
# read bucket name, templatized, if left unchanged will default to sagemaker-fmbench-read-{region}-{account_id}
read_bucket: {read_bucket}
# S3 prefix in the read bucket where deployment and inference scripts should be placed
scripts_prefix: scripts
# deployment and inference script files to be downloaded are placed in this list
# only needed if you are creating a new deployment script or inference script
# your HuggingFace token does need to be in this list and should be called "hf_token.txt"
script_files:
- hf_token.txt
# configuration files (like this one) are placed in this prefix
configs_prefix: configs
# list of configuration files to download, for now only pricing.yml needs to be downloaded
config_files:
- pricing.yml
# S3 prefix for the dataset files
source_data_prefix: source_data
# list of dataset files, the list below is from the LongBench dataset https://huggingface.co/datasets/THUDM/LongBench
source_data_files:
- 2wikimqa_e.jsonl
- 2wikimqa.jsonl
- hotpotqa_e.jsonl
- hotpotqa.jsonl
- narrativeqa.jsonl
- triviaqa_e.jsonl
- triviaqa.jsonl
# S3 prefix for the tokenizer to be used with the models
# NOTE 1: the same tokenizer is used with all the models being tested through a config file
# NOTE 2: place your model specific tokenizers in a prefix named as <model_name>_tokenizer
# so the mistral tokenizer goes in mistral_tokenizer, Llama2 tokenizer goes in llama2_tokenizer
tokenizer_prefix: tokenizer
# S3 prefix for prompt templates
prompt_template_dir: prompt_template
# prompt template to use, NOTE: same prompt template gets used for all models being tested through a config file
# the FMBench repo already contains a bunch of prompt templates so review those first before creating a new one
prompt_template_file: prompt_template_llama2.txt
# steps to run, usually all of these would be
# set to yes so nothing needs to change here
# you could, however, bypass some steps for example
# set the 2_deploy_model.ipynb to no if you are re-running
# the same config file and the model is already deployed
run_steps:
0_setup.ipynb: yes
1_generate_data.ipynb: yes
2_deploy_model.ipynb: yes
3_run_inference.ipynb: yes
4_model_metric_analysis.ipynb: yes
5_cleanup.ipynb: yes
# dataset related configuration
datasets:
# Refer to the 1_generate_data.ipynb notebook
# the dataset you use is expected to have the
# columns you put in prompt_template_keys list
# and your prompt template also needs to have
# the same placeholders (refer to the prompt template folder)
prompt_template_keys:
- input
- context
# if your dataset has multiple languages and it has a language
# field then you could filter it for a language. Similarly,
# you can filter your dataset to only keep prompts between
# a certain token length limit (the token length is determined
# using the tokenizer you provide in the tokenizer_prefix prefix in the
# read S3 bucket). Each of the array entries below create a payload file
# containing prompts matching the language and token length criteria.
filters:
- language: en
min_length_in_tokens: 1
max_length_in_tokens: 500
payload_file: payload_en_1-500.jsonl
- language: en
min_length_in_tokens: 500
max_length_in_tokens: 1000
payload_file: payload_en_500-1000.jsonl
- language: en
min_length_in_tokens: 1000
max_length_in_tokens: 2000
payload_file: payload_en_1000-2000.jsonl
- language: en
min_length_in_tokens: 2000
max_length_in_tokens: 3000
payload_file: payload_en_2000-3000.jsonl
- language: en
min_length_in_tokens: 3000
max_length_in_tokens: 3840
payload_file: payload_en_3000-3840.jsonl
# While the tests would run on all the datasets
# configured in the experiment entries below but
# the price:performance analysis is only done for 1
# dataset which is listed below as the dataset_of_interest
metrics:
dataset_of_interest: en_2000-3000
# all pricing information is in the pricing.yml file
# this file is provided in the repo. You can add entries
# to this file for new instance types and new Bedrock models
pricing: pricing.yml
# inference parameters, these are added to the payload
# for each inference request. The list here is not static
# any parameter supported by the inference container can be
# added to the list. Put the sagemaker parameters in the sagemaker
# section, bedrock parameters in the bedrock section (not shown here).
# Use the section name (sagemaker in this example) in the inference_spec.parameter_set
# section under experiments.
inference_parameters:
sagemaker:
do_sample: yes
temperature: 0.1
top_p: 0.92
top_k: 120
max_new_tokens: 100
return_full_text: False
# Configuration for experiments to be run. The experiments section is an array
# so more than one experiments can be added, these could belong to the same model
# but different instance types, or different models, or even different hosting
# options (such as one experiment is SageMaker and the other is Bedrock).
experiments:
- name: llama2-7b-g5.xlarge-huggingface-pytorch-tgi-inference-2.0.1-tgi1.1.0
# model_id is interpreted in conjunction with the deployment_script, so if you
# use a JumpStart model id then set the deployment_script to jumpstart.py.
# if deploying directly from HuggingFace this would be a HuggingFace model id
# see the DJL serving deployment script in the code repo for reference.
model_id: meta-textgeneration-llama-2-7b-f
model_version: "3.*"
model_name: llama2-7b-f
ep_name: llama-2-7b-g5xlarge
instance_type: "ml.g5.xlarge"
image_uri: '763104351884.dkr.ecr.{region}.amazonaws.com/huggingface-pytorch-tgi-inference:2.0.1-tgi1.1.0-gpu-py39-cu118-ubuntu20.04'
deploy: yes
instance_count: 1
# FMBench comes packaged with multiple deployment scripts, such as scripts for JumpStart
# scripts for deploying using DJL DeepSpeed, tensorRT etc. You can also add your own.
# See repo for details
deployment_script: jumpstart.py
# FMBench comes packaged with multiple inference scripts, such as scripts for SageMaker
# and Bedrock. You can also add your own. See repo for details
inference_script: sagemaker_predictor.py
inference_spec:
# this should match one of the sections in the inference_parameters section above
parameter_set: sagemaker
# runs are done for each combination of payload file and concurrency level
payload_files:
- payload_en_1-500.jsonl
- payload_en_500-1000.jsonl
- payload_en_1000-2000.jsonl
- payload_en_2000-3000.jsonl
# concurrency level refers to number of requests sent in parallel to an endpoint
# the next set of requests is sent once responses for all concurrent requests have
# been received.
concurrency_levels:
- 1
- 2
- 4
# Added for models that require accepting a EULA
accept_eula: true
# Environment variables to be passed to the container
# this is not a fixed list, you can add more parameters as applicable.
env:
SAGEMAKER_PROGRAM: "inference.py"
ENDPOINT_SERVER_TIMEOUT: "3600"
MODEL_CACHE_ROOT: "/opt/ml/model"
SAGEMAKER_ENV: "1"
HF_MODEL_ID: "/opt/ml/model"
MAX_INPUT_LENGTH: "4095"
MAX_TOTAL_TOKENS: "4096"
SM_NUM_GPUS: "1"
SAGEMAKER_MODEL_SERVER_WORKERS: "1"
- name: llama2-7b-g5.2xlarge-huggingface-pytorch-tgi-inference-2.0.1-tgi1.1.0
model_id: meta-textgeneration-llama-2-7b-f
model_version: "3.*"
model_name: llama2-7b-f
ep_name: llama-2-7b-g5-2xlarge
instance_type: "ml.g5.2xlarge"
image_uri: '763104351884.dkr.ecr.{region}.amazonaws.com/huggingface-pytorch-tgi-inference:2.0.1-tgi1.1.0-gpu-py39-cu118-ubuntu20.04'
deploy: yes
instance_count: 1
deployment_script: jumpstart.py
inference_script: sagemaker_predictor.py
inference_spec:
parameter_set: sagemaker
payload_files:
- payload_en_1-500.jsonl
- payload_en_500-1000.jsonl
- payload_en_1000-2000.jsonl
- payload_en_2000-3000.jsonl
concurrency_levels:
- 1
- 2
- 4
accept_eula: true
env:
SAGEMAKER_PROGRAM: "inference.py"
ENDPOINT_SERVER_TIMEOUT: "3600"
MODEL_CACHE_ROOT: "/opt/ml/model"
SAGEMAKER_ENV: "1"
HF_MODEL_ID: "/opt/ml/model"
MAX_INPUT_LENGTH: "4095"
MAX_TOTAL_TOKENS: "4096"
SM_NUM_GPUS: "1"
SAGEMAKER_MODEL_SERVER_WORKERS: "1"
report:
latency_budget: 2
cost_per_10k_txn_budget: 20
error_rate_budget: 0
per_inference_request_file: per_inference_request_results.csv
all_metrics_file: all_metrics.csv
txn_count_for_showing_cost: 10000
v_shift_w_single_instance: 0.025
v_shift_w_gt_one_instance: 0.025
🚨 Benchmarking Llama3 on Amazon SageMaker 🚨
Llama3 is now available on SageMaker (read blog post), and you can now benchmark it using FMBench. Here are the config files for benchmarking Llama3-8b-instruct and Llama3-70b-instruct on ml.p4d.24xlarge and ml.g5.12xlarge instance.
- Config file for
Llama3-8b-instructonml.p4d.24xlargeandml.g5.12xlarge - Config file for
Llama3-70b-instructonml.p4d.24xlargeandml.g5.12xlarge
Benchmarking Llama2 on Amazon SageMaker
Llama2 models are available through SageMaker JumpStart as well as directly deployable from Hugging Face to a SageMaker endpoint. You can use FMBench to benchmark Llama2 on SageMaker for different combinations of instance types and inference containers.
- Config file for
Llama2-7bonml.g5.xlargeandml.g5.2xlargeinstances, using the Hugging Face TGI container. - Config file for
Llama2-7bonml.g4dn.12xlargeinstance using the Deep Java Library DeepSpeed container. - Config file for
Llama2-13bonml.g5.12xlarge,ml.inf2.24xlargeandml.p4d.24xlargeinstances using the Hugging Face TGI container and the Deep Java Library & NeuronX container. - Config file for
Llama2-70bonml.p4d.24xlargeinstance using the Deep Java Library TensorRT container. - Config file for
Llama2-70bonml.inf2.48xlargeinstance using the HuggingFace TGI with Optimum NeuronX container.
Benchmarking Llama2 on Amazon Bedrock
The Llama2-13b-chat and Llama2-70b-chat models are available on Bedrock. You can use FMBench to benchmark Llama2 on Bedrock for both on-demand throughput and provisioned throughput inference options.
Config file for
Llama2-13b-chatandLlama2-70b-chaton Bedrock for on-demand throughput.For testing provisioned throughput simply replace the
ep_nameparameter inexperimentssection of the config file with the ARN of your provisioned throughput.