Jeff Tang
7298487dbc
updated tutorial and added llama_chatbot.py
Jeff Tang
7298487dbc
updated tutorial and added llama_chatbot.py
|
před 1 rokem | |
|---|---|---|
| .. | ||
| HelloLlamaCloud.ipynb | před 1 rokem | |
| HelloLlamaLocal.ipynb | před 1 rokem | |
| LiveData.ipynb | před 1 rokem | |
| Llama2_Gradio.ipynb | před 1 rokem | |
| README.md | před 1 rokem | |
| StructuredLlama.ipynb | před 1 rokem | |
| VideoSummary.ipynb | před 1 rokem | |
| csv2db.py | před 1 rokem | |
| llama-on-prem.md | před 1 rokem | |
| llama2-gradio.png | před 1 rokem | |
| llama2-streamlit.png | před 1 rokem | |
| llama2-streamlit2.png | před 1 rokem | |
| llama2.pdf | před 1 rokem | |
| llama_chatbot.py | před 1 rokem | |
| nba.txt | před 1 rokem | |
| streamlit_llama2.py | před 1 rokem | |
| txt2csv.py | před 1 rokem | |
| whatsapp_dashboard.jpg | před 1 rokem | |
| whatsapp_llama2.md | před 1 rokem | |
| whatsapp_llama_arch.jpg | před 1 rokem | |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
README.md
Llama 2 Demo Apps
This folder contains a series of Llama 2-powered apps:
- Quickstart Llama deployments and basic interactions with Llama
- Llama on your Mac and ask Llama general questions
- Llama on Google Colab
- Llama on Cloud and ask Llama questions about unstructured data in a PDF
Llama on-prem with vLLM and TGI
Specialized Llama use cases:
Ask Llama to summarize a video content
Ask Llama questions about structured data in a DB
Ask Llama questions about live data on the web
Build a Llama-enabled WhatsApp chatbot
We also show how to build quick web UI for Llama 2 demo apps using Streamlit and Gradio.
If you need a general understanding of GenAI, Llama 2, prompt engineering and RAG (Retrieval Augmented Generation), be sure to first check the Getting to know Llama 2 notebook and its Meta Connect video here.
More advanced Llama 2 demo apps will be coming soon.
Setting Up Environment
The quickest way to test run the notebook demo apps on your local machine is to create a Conda envinronment and start running the Jupyter notebook as follows:
conda create -n llama-demo-apps python=3.8
conda activate llama-demo-apps
pip install jupyter
cd <your_work_folder>
git clone https://github.com/facebookresearch/llama-recipes
cd llama-recipes/llama-demo-apps
jupyter notebook
You can also upload the notebooks to Google Colab.
HelloLlama - Quickstart in Running Llama2 (Almost) Everywhere*
The first three demo apps show:
- how to run Llama2 locally on a Mac, in the Google Colab notebook, and in the cloud using Replicate;
- how to use LangChain, an open-source framework for building LLM apps, to ask Llama general questions in different ways;
- how to use LangChain to load a recent PDF doc - the Llama2 paper pdf - and ask questions about it. This is the well known RAG method to let LLM such as Llama2 be able to answer questions about the data not publicly available when Llama2 was trained, or about your own data. RAG is one way to prevent LLM's hallucination.
- how to ask follow up questions to Llama by sending previous questions and answers as the context along with the new question, hence performing multi-turn chat or conversation with Llama.
Running Llama2 Locally on Mac
To run Llama2 locally on Mac using llama-cpp-python, first open the notebook HelloLlamaLocal. Then replace <path-to-llama-gguf-file> in the notebook HelloLlamaLocal with the path either to your downloaded quantized model file here, or to the ggml-model-q4_0.gguf file built with the following commands:
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
python3 -m pip install -r requirements.txt
python convert.py <path_to_your_downloaded_llama-2-13b_model>
./quantize <path_to_your_downloaded_llama-2-13b_model>/ggml-model-f16.gguf <path_to_your_downloaded_llama-2-13b_model>/ggml-model-q4_0.gguf q4_0
Running Llama2 Hosted in the Cloud
The HelloLlama cloud version uses LangChain with Llama2 hosted in the cloud on Replicate. The demo shows how to ask Llama general questions and follow up questions, and how to use LangChain to ask Llama2 questions about unstructured data stored in a PDF.
Note on using Replicate To run some of the demo apps here, you'll need to first sign in with Replicate with your github account, then create a free API token here that you can use for a while. After the free trial ends, you'll need to enter billing info to continue to use Llama2 hosted on Replicate - according to Replicate's Run time and cost for the Llama2-13b-chat model used in our demo apps, the model "costs $0.000725 per second. Predictions typically complete within 10 seconds." This means each call to the Llama2-13b-chat model costs less than $0.01 if the call completes within 10 seconds. If you want absolutely no costs, you can refer to the section "Running Llama2 locally on Mac" above or the "Running Llama2 in Google Colab" below.
Running Llama2 in Google Colab
To run Llama2 in Google Colab using llama-cpp-python, download the quantized Llama2-13b-chat model ggml-model-q4_0.gguf here, or follow the instructions above to build it, before uploading it to your Google drive. Note that on the free Colab T4 GPU, the call to Llama could take more than 20 minnutes to return; running the notebook locally on M1 MBP takes about 20 seconds.
Running Llama2 On-Prem with vLLM and TGI
This tutorial shows how to use Llama 2 with vLLM and Hugging Face TGI to build Llama 2 on-prem apps.
* To run a quantized Llama2 model on iOS and Android, you can use the open source MLC LLM or llama.cpp. You can even make a Linux OS that boots to Llama2 (repo).
VideoSummary: Ask Llama2 to Summarize a YouTube Video
This demo app uses Llama2 to return a text summary of a YouTube video. It shows how to retrieve the caption of a YouTube video and how to ask Llama to summarize the content in four different ways, from the simplest naive way that works for short text to more advanced methods of using LangChain's map_reduce and refine to overcome the 4096 limit of Llama's max input token size.
NBA2023-24: Ask Llama2 about Structured Data
This demo app shows how to use LangChain and Llama2 to let users ask questions about structured data stored in a SQL DB. As the 2023-24 NBA season is around the corner, we use the NBA roster info saved in a SQLite DB to show you how to ask Llama2 questions about your favorite teams or players.
LiveData: Ask Llama2 about Live Data
This demo app shows how to perform live data augmented generation tasks with Llama2 and LlamaIndex, another leading open-source framework for building LLM apps: it uses the You.com serarch API to get live search result and ask Llama2 about them.
WhatsApp Chatbot: Building a Llama-enabled WhatsApp Chatbot
This step-by-step tutorial shows how to use the WhatsApp Business API, LangChain and Replicate to build a Llama-enabled WhatsApp chatbot.
Quick Web UI for Llama2 Chat
If you prefer to see Llama2 in action in a web UI, instead of the notebooks above, you can try one of the two methods:
Running Streamlit with Llama2
Open a Terminal, run the following commands:
pip install streamlit langchain replicate
git clone https://github.com/facebookresearch/llama-recipes
cd llama-recipes/llama-demo-apps
Replace the <your replicate api token> in streamlit_llama2.py with your API token created here - for more info, see the note above.
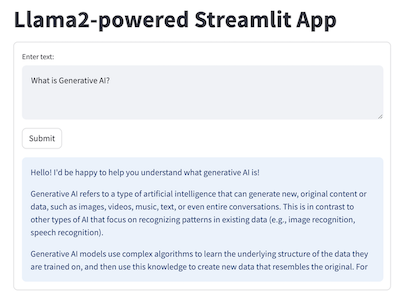
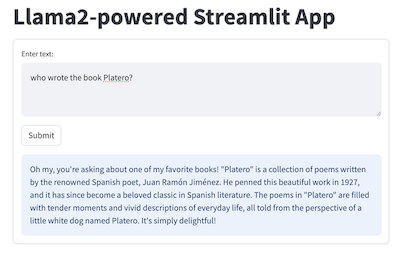
Then run the command streamlit run streamlit_llama2.py and you'll see on your browser the following UI with question and answer - you can enter new text question, click Submit, and see Llama2's answer:
Running Gradio with Llama2
To see how to query Llama2 and get answers with the Gradio UI both from the notebook and web, just launch the notebook Llama2_Gradio.ipynb, replace the <your replicate api token> with your API token created here - for more info, see the note above.
Then enter your question, click Submit. You'll see in the notebook or a browser with URL http://127.0.0.1:7860 the following UI: