|
|
@@ -1,12 +1,10 @@
|
|
|
# Llama 2 Fine-tuning / Inference Recipes, Examples and Demo Apps
|
|
|
|
|
|
-**[Update Oct. 20, 2023] We have just released a series of Llama 2 demo apps [here](./demo_apps). These apps show how to run Llama 2 locally and in the cloud to chat about data (PDF, DB, or live) and generate video summary.**
|
|
|
-
|
|
|
+**[Update Nov. 14, 2023] We recently released a series of Llama 2 demo apps [here](./demo_apps). These apps show how to run Llama 2 locally, in the cloud, on-prem or with WhatsApp, and how to ask Llama 2 questions in general and about custom data (PDF, DB, or live).**
|
|
|
|
|
|
The 'llama-recipes' repository is a companion to the [Llama 2 model](https://github.com/facebookresearch/llama). The goal of this repository is to provide examples to quickly get started with fine-tuning for domain adaptation and how to run inference for the fine-tuned models. For ease of use, the examples use Hugging Face converted versions of the models. See steps for conversion of the model [here](#model-conversion-to-hugging-face).
|
|
|
|
|
|
-In addition, we also provide a number of demo apps, to showcase the Llama2 usage along with other ecosystem solutions to run Llama2 locally on your mac and on cloud.
|
|
|
-
|
|
|
+In addition, we also provide a number of demo apps, to showcase the Llama 2 usage along with other ecosystem solutions to run Llama 2 locally, in the cloud, and on-prem.
|
|
|
|
|
|
Llama 2 is a new technology that carries potential risks with use. Testing conducted to date has not — and could not — cover all scenarios. In order to help developers address these risks, we have created the [Responsible Use Guide](https://github.com/facebookresearch/llama/blob/main/Responsible-Use-Guide.pdf). More details can be found in our research paper as well. For downloading the models, follow the instructions on [Llama 2 repo](https://github.com/facebookresearch/llama).
|
|
|
|
|
|
@@ -23,8 +21,6 @@ Llama 2 is a new technology that carries potential risks with use. Testing condu
|
|
|
6. [Repository Organization](#repository-organization)
|
|
|
7. [License and Acceptable Use Policy](#license)
|
|
|
|
|
|
-
|
|
|
-
|
|
|
# Quick Start
|
|
|
|
|
|
[Llama 2 Jupyter Notebook](./examples/quickstart.ipynb): This jupyter notebook steps you through how to finetune a Llama 2 model on the text summarization task using the [samsum](https://huggingface.co/datasets/samsum). The notebook uses parameter efficient finetuning (PEFT) and int8 quantization to finetune a 7B on a single GPU like an A10 with 24GB gpu memory.
|
|
|
@@ -184,14 +180,16 @@ You can read more about our fine-tuning strategies [here](./docs/LLM_finetuning.
|
|
|
# Demo Apps
|
|
|
This folder contains a series of Llama2-powered apps:
|
|
|
* Quickstart Llama deployments and basic interactions with Llama
|
|
|
- 1. Llama on your Mac and ask Llama general questions
|
|
|
- 2. Llama on Google Colab
|
|
|
- 3. Llama on Cloud and ask Llama questions about unstructured data in a PDF
|
|
|
+1. Llama on your Mac and ask Llama general questions
|
|
|
+2. Llama on Google Colab
|
|
|
+3. Llama on Cloud and ask Llama questions about unstructured data in a PDF
|
|
|
+4. Llama on-prem with vLLM and TGI
|
|
|
|
|
|
* Specialized Llama use cases:
|
|
|
- 1. Ask Llama to summarize a video content
|
|
|
- 2. Ask Llama questions about structured data in a DB
|
|
|
- 3. Ask Llama questions about live data on the web
|
|
|
+1. Ask Llama to summarize a video content
|
|
|
+2. Ask Llama questions about structured data in a DB
|
|
|
+3. Ask Llama questions about live data on the web
|
|
|
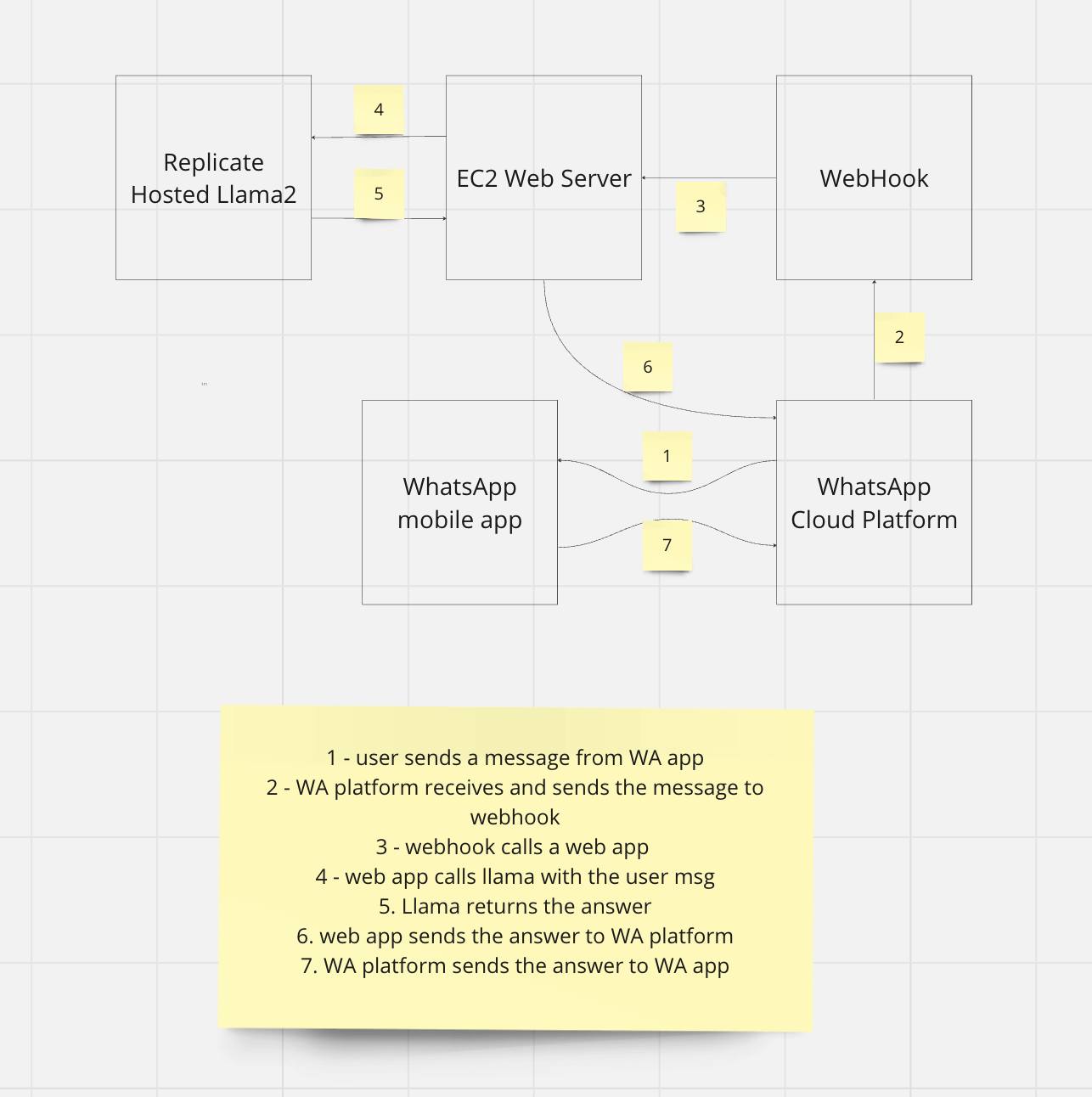
+4. Build a Llama-enabled WhatsApp chatbot
|
|
|
|
|
|
# Repository Organization
|
|
|
This repository is organized in the following way:
|

 gaopengzhi
gaopengzhi
{kind=link}
{kind=link}