
Parcourir la source
Merging latest from main
 Beto
Beto
45 fichiers modifiés avec 4763 ajouts et 326 suppressions
+ 26
- 6
README.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
Fichier diff supprimé car celui-ci est trop grand
+ 433
- 0
demo_apps/HelloLlamaCloud.ipynb
Fichier diff supprimé car celui-ci est trop grand
+ 347
- 0
demo_apps/HelloLlamaLocal.ipynb
+ 306
- 0
demo_apps/LiveData.ipynb
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 120
- 0
demo_apps/Llama2_Gradio.ipynb
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
Fichier diff supprimé car celui-ci est trop grand
+ 101
- 0
demo_apps/README.md
Fichier diff supprimé car celui-ci est trop grand
+ 559
- 0
demo_apps/StructuredLlama.ipynb
Fichier diff supprimé car celui-ci est trop grand
+ 698
- 0
demo_apps/VideoSummary.ipynb
+ 38
- 0
demo_apps/csv2db.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
BIN
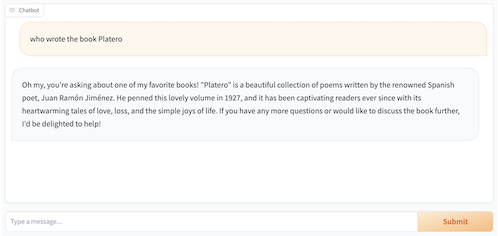
demo_apps/llama2-gradio.png
{kind=link}
BIN
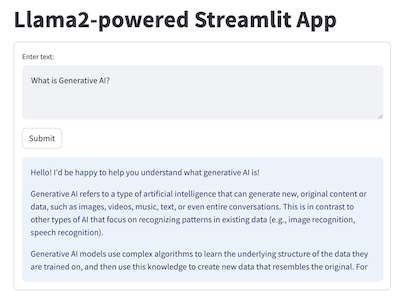
demo_apps/llama2-streamlit.png
{kind=link}
BIN
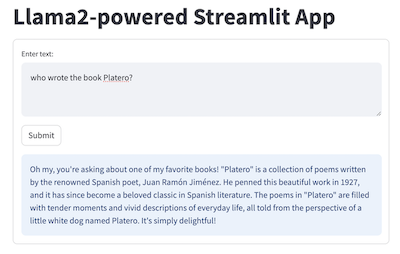
demo_apps/llama2-streamlit2.png
{kind=link}
BIN
demo_apps/llama2.pdf
Fichier diff supprimé car celui-ci est trop grand
+ 1294
- 0
demo_apps/nba.txt
+ 22
- 0
demo_apps/streamlit_llama2.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 53
- 0
demo_apps/txt2csv.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 15
- 3
docs/Dataset.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
Fichier diff supprimé car celui-ci est trop grand
+ 21
- 7
docs/FAQ.md
Fichier diff supprimé car celui-ci est trop grand
+ 1
- 0
examples/Getting_to_know_Llama.ipynb
+ 1
- 1
examples/README.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 23
- 30
examples/custom_dataset.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 3
- 6
examples/quickstart.ipynb
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 29
- 1
scripts/spellcheck_conf/wordlist.txt
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 2
src/llama_recipes/configs/datasets.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 2
- 4
src/llama_recipes/configs/training.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 2
- 0
src/llama_recipes/data/__init__.py
|
||
|
||
|
||
+ 34
- 0
src/llama_recipes/data/concatenator.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 57
- 0
src/llama_recipes/data/sampler.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 4
- 14
src/llama_recipes/datasets/alpaca_dataset.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 13
- 18
src/llama_recipes/datasets/grammar_dataset/grammar_dataset.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 3
- 3
src/llama_recipes/datasets/grammar_dataset/grammar_dataset_process.ipynb
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 19
- 13
src/llama_recipes/datasets/samsum_dataset.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 66
src/llama_recipes/datasets/utils.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 25
- 37
src/llama_recipes/finetuning.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 49
- 11
src/llama_recipes/utils/config_utils.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 6
- 6
src/llama_recipes/utils/dataset_utils.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 37
- 33
src/llama_recipes/utils/train_utils.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 18
- 0
tests/conftest.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 40
- 13
tests/datasets/test_custom_dataset.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 54
- 0
tests/datasets/test_grammar_datasets.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 30
- 14
tests/datasets/test_samsum_datasets.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 94
- 0
tests/test_batching.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 82
- 33
tests/test_finetuning.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 86
- 0
tests/test_sampler.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 18
- 5
tests/test_train_utils.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||