
فهرست منبع
Merge branch 'main' into l3p/llama_guard
 Beto
Beto
27فایلهای تغییر یافته به همراه809 افزوده شده و 166 حذف شده
+ 2
- 1
recipes/README.md
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 21
- 5
recipes/finetuning/datasets/custom_dataset.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 6
- 6
recipes/inference/local_inference/chat_completion/chat_completion.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 2
- 3
recipes/inference/local_inference/inference.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 156
- 0
recipes/multilingual/README.md
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 52
- 0
recipes/multilingual/extend_tokenizer.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
BIN
recipes/multilingual/imgs/phase1-eval-loss.png
{kind=link}
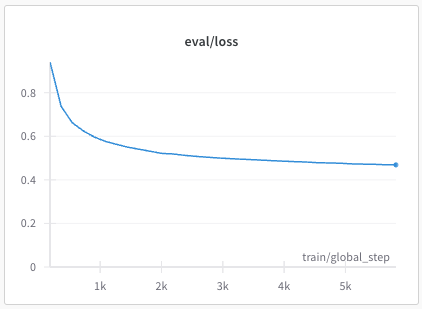
BIN
recipes/multilingual/imgs/phase1-train-loss.png
{kind=link}
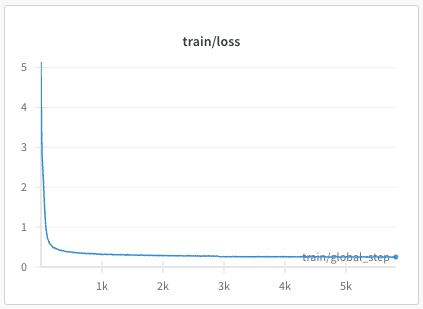
BIN
recipes/multilingual/imgs/phase2-eval-loss.png
{kind=link}
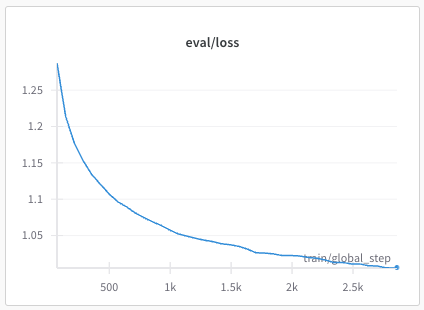
BIN
recipes/multilingual/imgs/phase2-train-loss.png
{kind=link}
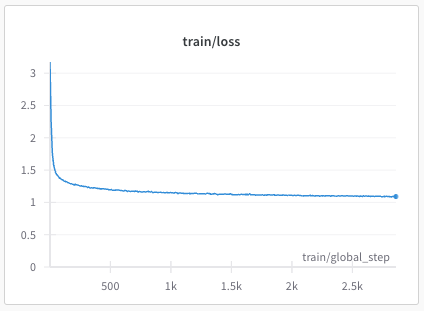
+ 23
- 0
recipes/multilingual/prepare_data.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 22
- 0
recipes/multilingual/train_tokenizer.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
تفاوت فایلی نمایش داده نمی شود زیرا این فایل بسیار بزرگ است
+ 196
- 0
recipes/responsible_ai/CodeShieldUsageDemo.ipynb
+ 1
- 1
requirements.txt
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 20
- 0
scripts/spellcheck_conf/wordlist.txt
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 1
- 0
src/llama_recipes/configs/training.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 3
- 4
src/llama_recipes/data/sampler.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 13
- 13
src/llama_recipes/finetuning.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 0
- 56
src/llama_recipes/inference/chat_utils.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 1
- 0
src/llama_recipes/utils/config_utils.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 15
- 10
tests/conftest.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 35
- 20
tests/datasets/test_custom_dataset.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 19
- 9
tests/datasets/test_grammar_datasets.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 19
- 8
tests/datasets/test_samsum_datasets.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 21
- 11
tests/test_batching.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 155
- 0
tests/test_chat_completion.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 26
- 19
tests/test_finetuning.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||