
Преглед на файлове
Merging Readme notes
 Beto
Beto
променени са 34 файла, в които са добавени 991 реда и са изтрити 407 реда
+ 0
- 125
LICENSE
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
Файловите разлики са ограничени, защото са твърде много
+ 16
- 15
README.md
+ 0
- 49
USE_POLICY.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 2
- 1
recipes/README.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 21
- 5
recipes/finetuning/datasets/custom_dataset.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 6
- 6
recipes/inference/local_inference/chat_completion/chat_completion.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 4
- 5
recipes/inference/local_inference/inference.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 156
- 0
recipes/multilingual/README.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 52
- 0
recipes/multilingual/extend_tokenizer.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
BIN
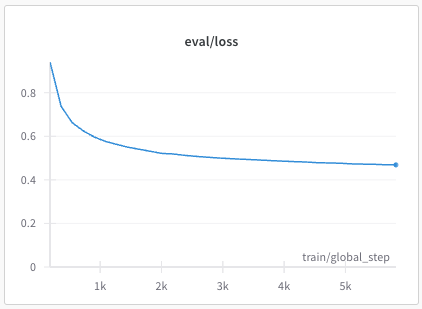
recipes/multilingual/imgs/phase1-eval-loss.png
{kind=link}
BIN
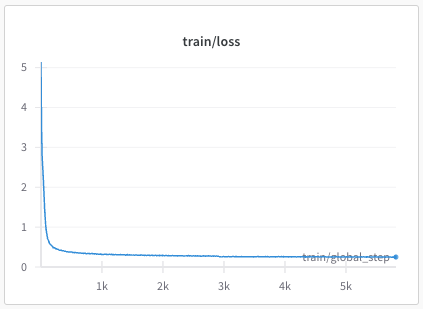
recipes/multilingual/imgs/phase1-train-loss.png
{kind=link}
BIN
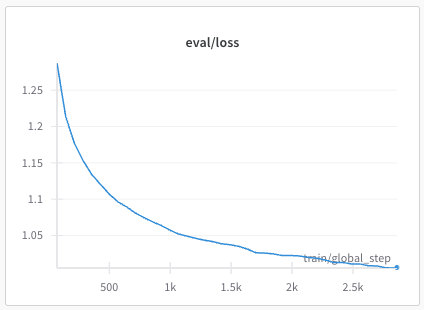
recipes/multilingual/imgs/phase2-eval-loss.png
{kind=link}
BIN
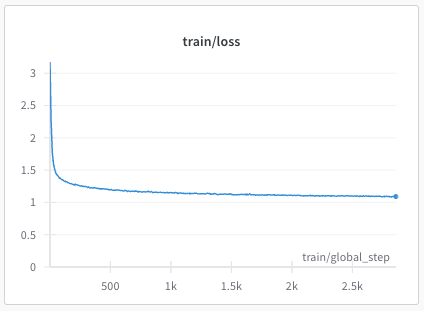
recipes/multilingual/imgs/phase2-train-loss.png
{kind=link}
+ 23
- 0
recipes/multilingual/prepare_data.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 22
- 0
recipes/multilingual/train_tokenizer.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
Файловите разлики са ограничени, защото са твърде много
+ 196
- 0
recipes/responsible_ai/CodeShieldUsageDemo.ipynb
+ 14
- 8
recipes/responsible_ai/llama_guard/README.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 28
- 21
recipes/responsible_ai/llama_guard/inference.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 1
- 1
requirements.txt
|
||
|
||
|
||
|
||
|
||
|
||
+ 20
- 0
scripts/spellcheck_conf/wordlist.txt
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 1
- 0
src/llama_recipes/configs/training.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 3
- 4
src/llama_recipes/data/sampler.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 13
- 13
src/llama_recipes/finetuning.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 56
src/llama_recipes/inference/chat_utils.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 117
- 18
src/llama_recipes/inference/prompt_format_utils.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 5
- 3
src/llama_recipes/inference/safety_utils.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 1
- 0
src/llama_recipes/utils/config_utils.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 15
- 10
tests/conftest.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 35
- 20
tests/datasets/test_custom_dataset.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 19
- 9
tests/datasets/test_grammar_datasets.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 19
- 8
tests/datasets/test_samsum_datasets.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 21
- 11
tests/test_batching.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 155
- 0
tests/test_chat_completion.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 26
- 19
tests/test_finetuning.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||