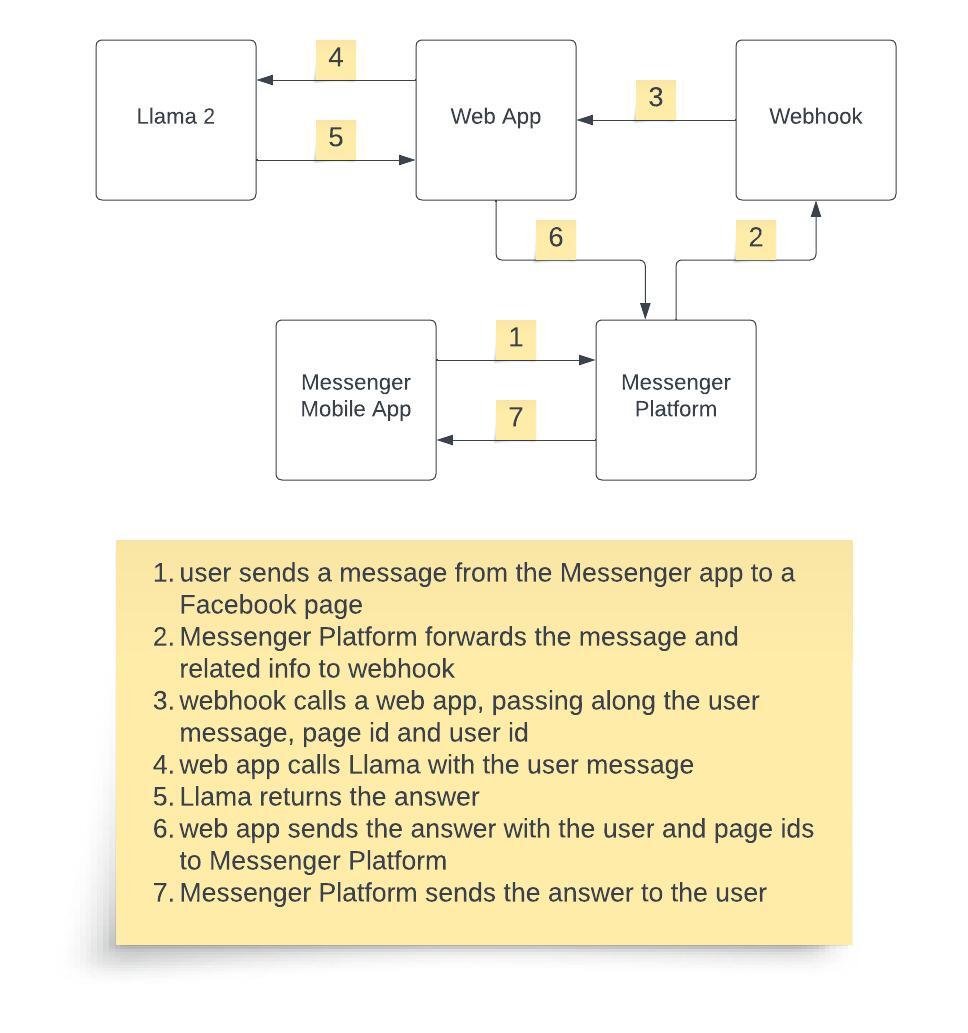
|
|
@@ -0,0 +1,163 @@
|
|
|
+import json
|
|
|
+import os
|
|
|
+from typing import List, Union
|
|
|
+
|
|
|
+import fire
|
|
|
+import torch
|
|
|
+from tqdm import tqdm
|
|
|
+from transformers import LlamaForCausalLM # @manual
|
|
|
+
|
|
|
+NUM_SHARDS = {
|
|
|
+ "7B": 1,
|
|
|
+ "13B": 2,
|
|
|
+ "34B": 4,
|
|
|
+ "30B": 4,
|
|
|
+ "65B": 8,
|
|
|
+ "70B": 8,
|
|
|
+}
|
|
|
+
|
|
|
+
|
|
|
+def write_model(model_path, model_size, output_base_path):
|
|
|
+ dtype = torch.bfloat16
|
|
|
+
|
|
|
+ params = json.load(open(os.path.join(output_base_path, "params.json"), "r"))
|
|
|
+ num_shards = NUM_SHARDS[model_size]
|
|
|
+ n_layers = params["n_layers"]
|
|
|
+ n_heads = params["n_heads"]
|
|
|
+ n_heads_per_shard = n_heads // num_shards
|
|
|
+ dim = params["dim"]
|
|
|
+ dims_per_head = dim // n_heads
|
|
|
+ base = 10000.0
|
|
|
+ inv_freq = (
|
|
|
+ 1.0 / (base ** (torch.arange(0, dims_per_head, 2).float() / dims_per_head))
|
|
|
+ ).to(dtype)
|
|
|
+
|
|
|
+ if "n_kv_heads" in params:
|
|
|
+ num_key_value_heads = params["n_kv_heads"] # for GQA / MQA
|
|
|
+ num_local_key_value_heads = n_heads_per_shard // num_key_value_heads
|
|
|
+ key_value_dim = dim // num_key_value_heads
|
|
|
+ else: # compatibility with other checkpoints
|
|
|
+ num_key_value_heads = n_heads
|
|
|
+ num_local_key_value_heads = n_heads_per_shard
|
|
|
+ key_value_dim = dim
|
|
|
+
|
|
|
+ model = LlamaForCausalLM.from_pretrained(
|
|
|
+ model_path,
|
|
|
+ torch_dtype=dtype,
|
|
|
+ low_cpu_mem_usage=True,
|
|
|
+ )
|
|
|
+ loaded = model.state_dict()
|
|
|
+
|
|
|
+ # permute for sliced rotary
|
|
|
+ def permute(w, n_heads=n_heads, dim1=dim, dim2=dim):
|
|
|
+ return (
|
|
|
+ w.view(n_heads, 2, dim1 // n_heads // 2, dim2)
|
|
|
+ .transpose(1, 2)
|
|
|
+ .reshape(dim1, dim2)
|
|
|
+ )
|
|
|
+
|
|
|
+ state_dict = [{} for _ in range(num_shards)]
|
|
|
+
|
|
|
+ def insert(name: str, tensor: Union[List, torch.Tensor]):
|
|
|
+ for i in range(num_shards):
|
|
|
+ state_dict[i][name] = (
|
|
|
+ tensor[i].clone() if isinstance(tensor, list) else tensor
|
|
|
+ )
|
|
|
+
|
|
|
+ def insert_chunk(name: str, tensor: torch.Tensor, dim: int):
|
|
|
+ tensors = tensor.chunk(num_shards, dim=dim)
|
|
|
+ for i, tensor in enumerate(tensors):
|
|
|
+ state_dict[i][name] = tensor.clone()
|
|
|
+
|
|
|
+ insert_chunk("tok_embeddings.weight", loaded["model.embed_tokens.weight"], 1)
|
|
|
+ insert("norm.weight", loaded["model.norm.weight"])
|
|
|
+ insert_chunk("output.weight", loaded["lm_head.weight"], 0)
|
|
|
+
|
|
|
+ for layer_i in tqdm(range(n_layers), desc="Converting layers"):
|
|
|
+
|
|
|
+ ts = (
|
|
|
+ permute(loaded[f"model.layers.{layer_i}.self_attn.q_proj.weight"])
|
|
|
+ .view(n_heads_per_shard * num_shards, dims_per_head, dim)
|
|
|
+ .chunk(num_shards, dim=0)
|
|
|
+ )
|
|
|
+ insert(f"layers.{layer_i}.attention.wq.weight", [t.view(-1, dim) for t in ts])
|
|
|
+
|
|
|
+ ts = (
|
|
|
+ permute(
|
|
|
+ loaded[f"model.layers.{layer_i}.self_attn.k_proj.weight"],
|
|
|
+ num_key_value_heads,
|
|
|
+ key_value_dim,
|
|
|
+ dim,
|
|
|
+ )
|
|
|
+ .view(num_local_key_value_heads * num_shards, dims_per_head, dim)
|
|
|
+ .chunk(num_shards, dim=0)
|
|
|
+ )
|
|
|
+ insert(f"layers.{layer_i}.attention.wk.weight", [t.view(-1, dim) for t in ts])
|
|
|
+
|
|
|
+ ts = (
|
|
|
+ loaded[f"model.layers.{layer_i}.self_attn.v_proj.weight"]
|
|
|
+ .view(num_local_key_value_heads * num_shards, dims_per_head, dim)
|
|
|
+ .chunk(num_shards, dim=0)
|
|
|
+ )
|
|
|
+ insert(f"layers.{layer_i}.attention.wv.weight", [t.view(-1, dim) for t in ts])
|
|
|
+
|
|
|
+ insert_chunk(
|
|
|
+ f"layers.{layer_i}.attention.wo.weight",
|
|
|
+ loaded[f"model.layers.{layer_i}.self_attn.o_proj.weight"],
|
|
|
+ 1,
|
|
|
+ )
|
|
|
+
|
|
|
+ insert_chunk(
|
|
|
+ f"layers.{layer_i}.feed_forward.w1.weight",
|
|
|
+ loaded[f"model.layers.{layer_i}.mlp.gate_proj.weight"],
|
|
|
+ 0,
|
|
|
+ )
|
|
|
+
|
|
|
+ insert_chunk(
|
|
|
+ f"layers.{layer_i}.feed_forward.w2.weight",
|
|
|
+ loaded[f"model.layers.{layer_i}.mlp.down_proj.weight"],
|
|
|
+ 1,
|
|
|
+ )
|
|
|
+
|
|
|
+ insert_chunk(
|
|
|
+ f"layers.{layer_i}.feed_forward.w3.weight",
|
|
|
+ loaded[f"model.layers.{layer_i}.mlp.up_proj.weight"],
|
|
|
+ 0,
|
|
|
+ )
|
|
|
+
|
|
|
+ insert(
|
|
|
+ f"layers.{layer_i}.attention_norm.weight",
|
|
|
+ loaded[f"model.layers.{layer_i}.input_layernorm.weight"],
|
|
|
+ )
|
|
|
+ insert(
|
|
|
+ f"layers.{layer_i}.ffn_norm.weight",
|
|
|
+ loaded[f"model.layers.{layer_i}.post_attention_layernorm.weight"],
|
|
|
+ )
|
|
|
+ insert("rope.freqs", inv_freq)
|
|
|
+
|
|
|
+ for i in tqdm(range(num_shards), desc="Saving checkpoint shards"):
|
|
|
+ torch.save(
|
|
|
+ state_dict[i], os.path.join(output_base_path, f"consolidated.{i:02d}.pth")
|
|
|
+ )
|
|
|
+
|
|
|
+
|
|
|
+def main(
|
|
|
+ model_path: str,
|
|
|
+ model_size: str,
|
|
|
+ output_dir: str,
|
|
|
+):
|
|
|
+ """Convert llama weights from huggingface format to consolidated format.
|
|
|
+ params:
|
|
|
+ model_path: model name or path to the model directory.
|
|
|
+ model_size: Llama model size, one of 7B, 13B, 34B, 30B, 65B, 70B.
|
|
|
+ output_dir: directory to save Llama weights, should contains params.json.
|
|
|
+ """
|
|
|
+ assert model_size in NUM_SHARDS, f"Unknown model size {model_size}"
|
|
|
+ params_path = os.path.join(output_dir, "params.json")
|
|
|
+ assert os.path.isfile(params_path), f"{params_path} does not exist"
|
|
|
+
|
|
|
+ write_model(model_path, model_size, output_dir)
|
|
|
+
|
|
|
+
|
|
|
+if __name__ == "__main__":
|
|
|
+ fire.Fire(main)
|

 Beto
Beto
{kind=link}
{kind=link}