
Bladeren bron
Llama2 demo apps - 6 notebooks to run Llama2, with llama-cpp, LangChain and LlamaIndex integration (#243)
 Hamid Shojanazeri
Hamid Shojanazeri
17 gewijzigde bestanden met toevoegingen van 4033 en 3 verwijderingen
+ 19
- 2
README.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
File diff suppressed because it is too large
+ 412
- 0
demo_apps/HelloLlamaCloud.ipynb
File diff suppressed because it is too large
+ 454
- 0
demo_apps/HelloLlamaLocal.ipynb
File diff suppressed because it is too large
+ 422
- 0
demo_apps/LiveData.ipynb
+ 96
- 0
demo_apps/Llama2_Gradio.ipynb
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
File diff suppressed because it is too large
+ 101
- 0
demo_apps/README.md
File diff suppressed because it is too large
+ 504
- 0
demo_apps/StructuredLlama.ipynb
File diff suppressed because it is too large
+ 591
- 0
demo_apps/VideoSummary.ipynb
+ 38
- 0
demo_apps/csv2db.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
BIN
demo_apps/llama2-gradio.png
{kind=link}

BIN
demo_apps/llama2-streamlit.png
{kind=link}
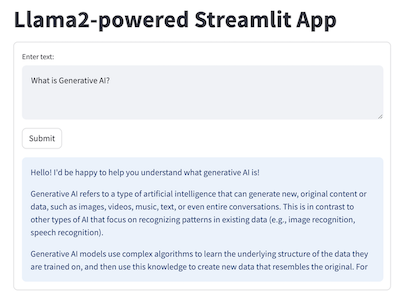
BIN
demo_apps/llama2-streamlit2.png
{kind=link}
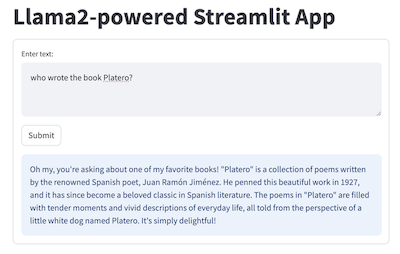
BIN
demo_apps/llama2.pdf
File diff suppressed because it is too large
+ 1294
- 0
demo_apps/nba.txt
+ 22
- 0
demo_apps/streamlit_llama2.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 53
- 0
demo_apps/txt2csv.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 27
- 1
scripts/spellcheck_conf/wordlist.txt
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||